池化技术 程序运行的本质:占用系统资源! 提高程序的使用率,降低我们一个性能消耗
线程池、连接池、内存池、对象池 …………
为什么要用线程池:线程复用
ExecutorService 三大方法、七大参数、4种拒绝策略 三大方法 package com.coding.pool;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;public class ThreadPoolDemo01 public static void main (String[] args) try { for (int i = 0 ; i < 30 ; i++) { threadPool.execute(()->{ System.out.println(Thread.currentThread().getName() + " ok" ); }); } } catch (Exception e) { e.printStackTrace(); } finally { threadPool.shutdown(); } } }
先看看这个三个方法的源码:
七大参数 new ThreadPoolExecutor(0 , Integer.MAX_VALUE, 60L , TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); new ThreadPoolExecutor(nThreads, nThreads, 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); ThreadPoolExecutor(1 , 1 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()) public ThreadPoolExecutor (int corePoolSize, // 核心池线程数大小 (常用) int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0 ) throw new IllegalArgumentException () ; if (workQueue == null || threadFactory == null || handler == null ) throw new NullPointerException(); this .acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this .corePoolSize = corePoolSize; this .maximumPoolSize = maximumPoolSize; this .workQueue = workQueue; this .keepAliveTime = unit.toNanos(keepAliveTime); this .threadFactory = threadFactory; this .handler = handler; }
自定义线程池的策略(推荐使用这种方式创建线程池、因为这样能让我们明确线程是怎样创建、销毁的,并且防止创建过多线程导致OOM异常)
package com.coding.pool;import java.util.concurrent.*;public class ThreadPoolDemo01 public static void main (String[] args) ExecutorService threadPool = new ThreadPoolExecutor( 2 , 5 , 3L , TimeUnit.SECONDS, new LinkedBlockingDeque<>(3 ), Executors.defaultThreadFactory(), new ThreadPoolExecutor.CallerRunsPolicy()); try { for (int i = 0 ; i < 100 ; i++) { threadPool.execute(()->{ System.out.println(Thread.currentThread().getName() + " ok" ); }); } } catch (Exception e) { e.printStackTrace(); } finally { threadPool.shutdown(); } } }
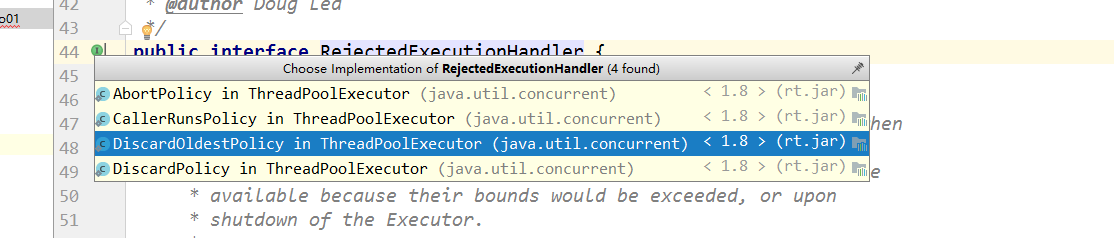
四大拒绝策略
什么时候会触发拒绝策略? 创建的任务>阻塞队列数量(new LinkedBlockingDeque<>(3))+maximumPoolSize时
请你谈谈 最大线程池 该如何设置? CPU密集型: 根据CPU的处理器数量来定!保证最大效率
IO密集型: 50 个线程都是进程操作大io资源, 比较耗时! > 这个常用的 IO 任务数!
ScheduledExecutorService ScheduledExecutorService 用于指定延时时间或者间隔时间来执行指定任务,继承于ExecutorService。 4个构造函数
点进去发现,其实就是调用了父类的7大参数的构造函数,我们不能自己调整最大线程数、线程超时时间。
按ExecutorService的规则来看,创建的线程超过corePoolSize+Queue队列数会自动增加线程数,通过测试发现,其实并不会增加执行的线程, new ScheduledThreadPoolExecutor(3)的线程数永远都是我们定义的3,如果我们创建6个线程执行,6个线程并不会同时计时,而是等待线程空闲后再开始计算延时!执行以下代码:
package vc.coding.juc;import java.time.LocalDateTime;import java.time.format.DateTimeFormatter;import java.util.concurrent.Executors;import java.util.concurrent.ScheduledExecutorService;import java.util.concurrent.ScheduledThreadPoolExecutor;import java.util.concurrent.TimeUnit;public class ScheduledExecutor1 private static ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(3 , Executors.defaultThreadFactory(), new ScheduledThreadPoolExecutor.AbortPolicy()); public static void main (String[] args) for (int i = 1 ; i <= 6 ; i++) { DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("mm:ss" ); scheduledExecutorService.schedule(() -> { try { TimeUnit.SECONDS.sleep(2 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("执行的时间" + dateTimeFormatter.format(LocalDateTime.now())); }, 2 , TimeUnit.SECONDS); } } }
执行结果:
执行的时间59:44
这样的话我们定义足够多的核心线程数不就行了?像这样: new ScheduledThreadPoolExecutor(10000)
ScheduledExecutorService可以用于订单延迟关闭,设备延迟离线的业务场景吗? 问题来了:我想应用去创建订单时同时创建延时任务,超时去取消订单,如果一瞬间来了1000个订单,是否会创建1000个线程,占用过多内存?执行以下代码:
package vc.coding.juc;import lombok.SneakyThrows;import java.time.LocalDateTime;import java.time.format.DateTimeFormatter;import java.util.concurrent.Executors;import java.util.concurrent.ScheduledExecutorService;import java.util.concurrent.ScheduledThreadPoolExecutor;import java.util.concurrent.TimeUnit;public class ScheduledExecutor private static ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(70 , Executors.defaultThreadFactory(), new ScheduledThreadPoolExecutor.AbortPolicy()); @SneakyThrows public static void main (String[] args) long startMemory = Runtime.getRuntime().freeMemory(); System.out.println("开始时内存" + startMemory); DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("mm:ss" ); for (int i = 1 ; i <= 50 ; i++) { System.out.println("创建时消耗内存:" + consumeMB(startMemory)); System.out.println("创建线程数:" + (Thread.activeCount() - 2 )); scheduledExecutorService.schedule(() -> { try { TimeUnit.SECONDS.sleep(5 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("执行完消耗内存" + consumeMB(startMemory) + "时间" + dateTimeFormatter.format(LocalDateTime.now())); }, 2 , TimeUnit.SECONDS); } while (true ) { System.out.println("-实时消耗内存" + consumeMB(startMemory)); TimeUnit.SECONDS.sleep(2 ); } } private static String consumeMB (long startMemory) return (startMemory - Runtime.getRuntime().freeMemory()) / 1024 / 1024 + "MB" ; } }
运行的结果确实,随着线程的不断创建,消耗的内存越来越多,这样下去很容易出现OOM异常。
总结 ScheduledExecutorService不适合订单结束、设备离线这类场景,适合一些对执行时机不必特别精准的,只需要晚于某个时间之后执行就行了的任务。下一篇
对于订单结束、设备离线这类场景,下一篇《采用延时队列实现延时任务》也许能为您提供解决的思路!